
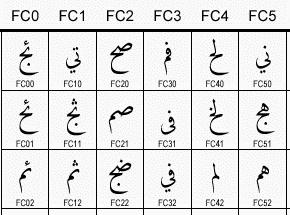
First of all, it should be made clear that the three tables collected and presented on the previous page are not all of Arabic-script "Unicode," only all of it that happens to interest the people at Sharmahd.
The Unicoders proper vouchsafe to humanity not only a code page of plain Arabic, but also Arabic "presentation forms" of two utterly different sorts. The sort that Sharmahd is interested in is the array of contextual forms of the alphabetic letters (absolute / final / initial / medial). That is what the second two of those three screen shots present.
The other sort of "presentation forms" is ligatures of two or more alphabetic letters. The former is, so to say, fractional letters, and the latter, multiple letters. Plus of course we still have the integral letters themselves at U+0600.
Further to unclarify things, this distinction has nothing at all to do with the difference between "Arabic Presentation Forms - A" and "Arabic Presentation Forms - B." You may see that the Sharmahd tables show contextual forms under both those rubrics indiscriminately. As one might perhaps have anticipated from this source, the A and B are assigned the wrong way around logically. It is the B table that contains the variant forms for the plain Arabic alphabet of the Arabs, whereas the A table gives only those added for Persian, Urdu and points east.
The ligatures are considered by the Unicoders to be part of "Arabic Presentation Forms - A." They come after the part of that range reproduced by Sharmahd and look like this:
Quite by accident that fragment of the ligature table happens to contain the single most common word in the Arabic language, namely,
(1) We could write the word in one fell swoop, using the ligature in "Presentation Forms - A":
(U+FC32) == في
(2) We could write the word taking account of contextual variants, initial F
plus final Y, invoking "Presentation Forms - B":
(U+FED3)(U+FEF2) == في
(3) We could write the word taking account only of the letters as such, generic F
plus generic Y, using the basic Arabic page:
(U+0641)(U+064A) == في
And in principle and given a longer word, we might even try mixing and all three approaches.
A Unicoder might respond that the first of these forms is (or could be) visibly different from the other two. Indeed. But she ccould hardly claim that the second two differ from one another even potentially.
Why µsoft Internet Explorer 5, in conjunction with µsoft Windows Millennium Edition, wants this word (written above always exactly the same way) to become a ligature in small "Courier" but to remain two semi-detached letters in larger "Tahoma," Redmond alone knows. That is an interesting question, but pertinent to the perplexities of "Unicode" only insofar as it reminds us that actual software writers are always going to have the upper hand over theoretical codifiers in the bitter end.
"Unicode" being an eternal ideological abstraction, it further does not matter that at the moment this triple ambiguity problem does not arise in practice because there aren't any fonts and software drivers for the "presentation forms." Such apparatus could, after all, conceivably come into existence. Perhaps it already has, somewhere outside the µsoft world of Windownet Explorer and Office 200X which we admittedly have an exaggerated tendency to consider the only real and serious world for Arabic computation. It doesn't matter that it would be pretty pointless for any vendor ever to instantiate the "presentation forms," since the U+0600 page is quite adequate by itself, given existing software to make it actually happen. Or we should perhaps say, any vendor whose business is not typography proper. If you were actually printing real bricks-and-mortar books in Arabic script, the ligatures would be of some importance. But as we have just seen on this very page, the existing software is already into that racket too -- without discernible reference to the Unicoders' magic numbers.
But, longius ut sit opus, the theorists should be allowed their day in court. What, in the Unicoders' official opinion, is a "presentation form"? We learn from their Glossary that a PF is a ligature or variant glyph that has been encoded as a character for compatibility. (See also compatibility character (1).
And a "compatibility character (1)" turns out to be a character encoded only for compatibility with preexisting character encoding standards to support transcoding and "transcoding" is defined as conversion of character data between different character sets. (Bonjour, M. Jourdain! Evidently we've been "transcoding" about as long as you have been talking prose.)
Different people will disagree about where intolerable jargon begins exactly. We don't mind "glyph" ourselves, but it should probably be explained that the word means one actual mark like you'd see on the printed page. Upper- and lower-case A are both the same letter, but they are different glyphs. Absolute, final, initial and medial variants in Arabic script are different glyphs. On the other hand, it is the same glyph in any size, typeface or color. The Unicoders' definitory fandango runs
Glyph. (1) An abstract form that represents one or more
glyph images.
(2) A synonym for glyph image. In displaying Unicode
character data, one or more glyphs may be selected
to depict a particular character. These glyphs are
selected by a rendering engine during composition
and layout processing. (See also character.)
Glyph Code. A numeric code that refers to a glyph. Usually,
the glyphs contained in a font are referenced by their
glyph code. Glyph codes may be local to a particular
font; that is, a different font containing the same
glyphs may use different codes.
Glyph Identifier. Similar to a glyph code, a glyph identifier is
a label used to refer to a glyph within a font. A font
may employ both local and global glyph identifiers. A
collection of global or universal glyph identifiers is
defined by the Association for Font Information and
Interchange (AFII).
Glyph Image. The actual, concrete image of a glyph representation
having been rasterized or otherwise imaged onto some
display surface.
A "presentation form," then, is a ligature or variant glyph encoded as a character for compatibility. The first part of this confirms our own amateur account of these mysteries above. PF's may be either multiple characters or integral characters or fractional characters. The theory of the theorists is clear enough, but their working it out becomes puzzling. Presumably the U+0600 page is supposed to be only the mainstream characters of Arabic script, but are not U+06A9، ک, and U+06AA in fact and by this definition "presentation forms" of U+0643, ك? Shouldn't they have been banished up to negative-number land? (With "Windows Persian," we don't have the equivalent of their U+06AA, so you will have to look at the table.) Nay, things are worse than that. The KKK problem is not just that these three items are not distinct characters (_sc._ letters of the alphabet), but that they aren't even "variant glyphs." They are merely the way different fonts realize one and the same thing. True, Karachi and Cairo do not have the same taste in typefaces, but is there really some obscure language where these three كافات coëxist as distinctively contrasting letters? If not, it makes no more sense -- in their own terms -- for the Unicoders to code them distinctively than to assign numbers for the differences between A and A.
A "presentation form" is a ligature or variant glyph encoded as a character for compatibility. But compatibility with what? Compatibilty of what with what? It is unlikely that anybody ever anticipated the Unicoders themselves in assigning the particular number 65,260 (0xFEEC) to medial haa', ـهـ. At the opposite extreme of specificity, mere compatibility with fourteen or fifteen centuries of established orthography requires that Arabic-script computation have that glyph around somewhere. Probably the "Unicode" crew were thinking only about Latin script when they invented the "presentation forms" category in the first place, which is rather unfortunate, since their generic "Alphabetic Presentation Forms" page
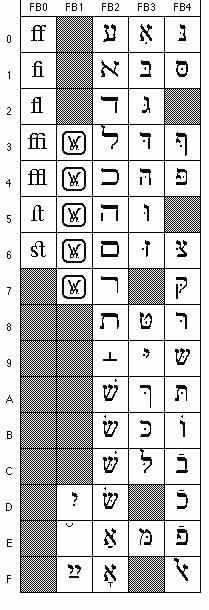
is a very paltry affair compared to what they turned out to need for Thana and Syriac and, oh yes, by the way, Arabic. Indeed, that picture makes us wonder if the whole vasty conceptualization of "presentation forms" might not all boil down to one individual at a particular committee meeting who had a fixation on compatibility with some preëxisting FF FI FL FFI FFL and ST. (Why not allow us a pretty CT, too, for Pete's sake? And how about that scrumptious capital Q that uncoils her tail underneath all the rest of the word? Now that would be a real challenge to توحيد الشفرة !)
Play it again, Sam, one last time: a "presentation form" is a ligature or variant glyph encoded as a character for compatibility. The wording reminds us of the Abraham Lincoln joke about whether or not a dog has five legs if you count the tail as a leg. If something is "encoded as a character," does that mean it really IS a character?
Our above exposé of the triple ambiguity about spelling fy assumed that tails are legs, that (U+FC32) is exactly the equal of (U+0641) characterwise. Perhaps that is not quite what the Unicoders intend. They perhaps lay it down somewhere amongst all their many layings-down that we are permitted to use "presentation forms" as characters only when we are in effect talking about typography and hymning the beauties of "Unicode," not when we are just writing Arabic. There is a genuine problem here, one we just stumbled over ourselves. One can not, with "Windows Persian," write ONLY the medial form of haa', what we actually wrote above has a kashide (تطويل) on either side to force the medial form to appear. If one could somehow treat that leg as a tail on special occasions, the single glyph itself could have been presented surrounded with white space.
So then in theory, the "Unicode" crew might disallow the supposedly synonymous orthographies above and say that only the last one would be valid unless the whole point of the discussion were the exact appearance of the "presentation form" glyphs.
The Unicoders might have so decreed, but it is doubtful that they actually did, because the Sharmahd people have thought it worth their time to give UniPad a font that includes the contextual-variant sort of "presentation forms." If it was against the regulations to use those glyphs as ordinary characters, they need not have bothered. If they wanted to make it possible for us to discuss all the details of Arabic-script "Unicode," they should have given us the ligatures also.
The ideal regulations for the Unicoders to promulgate magisterially and the Glyph Police to enforce stringently would be more complicated:
Something like that ought to do the trick.
link to "Unicode" Digital Library page